BlackLab Search Interface for the General Missives of the VOC¶
Date: 2021 (pre-GLOBALISE)
URL: https://corpora.ato.ivdnt.org/corpus-frontend/Missiven/search
Status: Production
People involved: Sophie Arnoult, Jesse de Does, Dirk Roorda, Jan Niestadt, Lodewijk Petram, Piek Vossen, Jessica den Oudsten, Daniël Tuik
A BlackLab search environment offers a new way to explore the General Missives of the Dutch East India Company (VOC). These reports, sent from Batavia (Jakarta) to the Dutch Republic between 1610 and 1795, are now accessible for in-depth research thanks to efforts within the CLARIAH project by a team from VU University, the Huygens Institute, and the Dutch Language Institute. Utilizing advanced OCR and Named Entity Recognition techniques1, the team enhanced these documents with metadata and structural elements, including annotations for entities like persons and locations.
The BlackLab interface facilitates computational analysis and robust search capabilities of the enriched texts. Researchers can now perform complex syntactic searches or simple keyword queries, uncovering nuanced historical and linguistic insights. A slightly cleaner version of the same corpus is also available as a Text-Fabric resource.
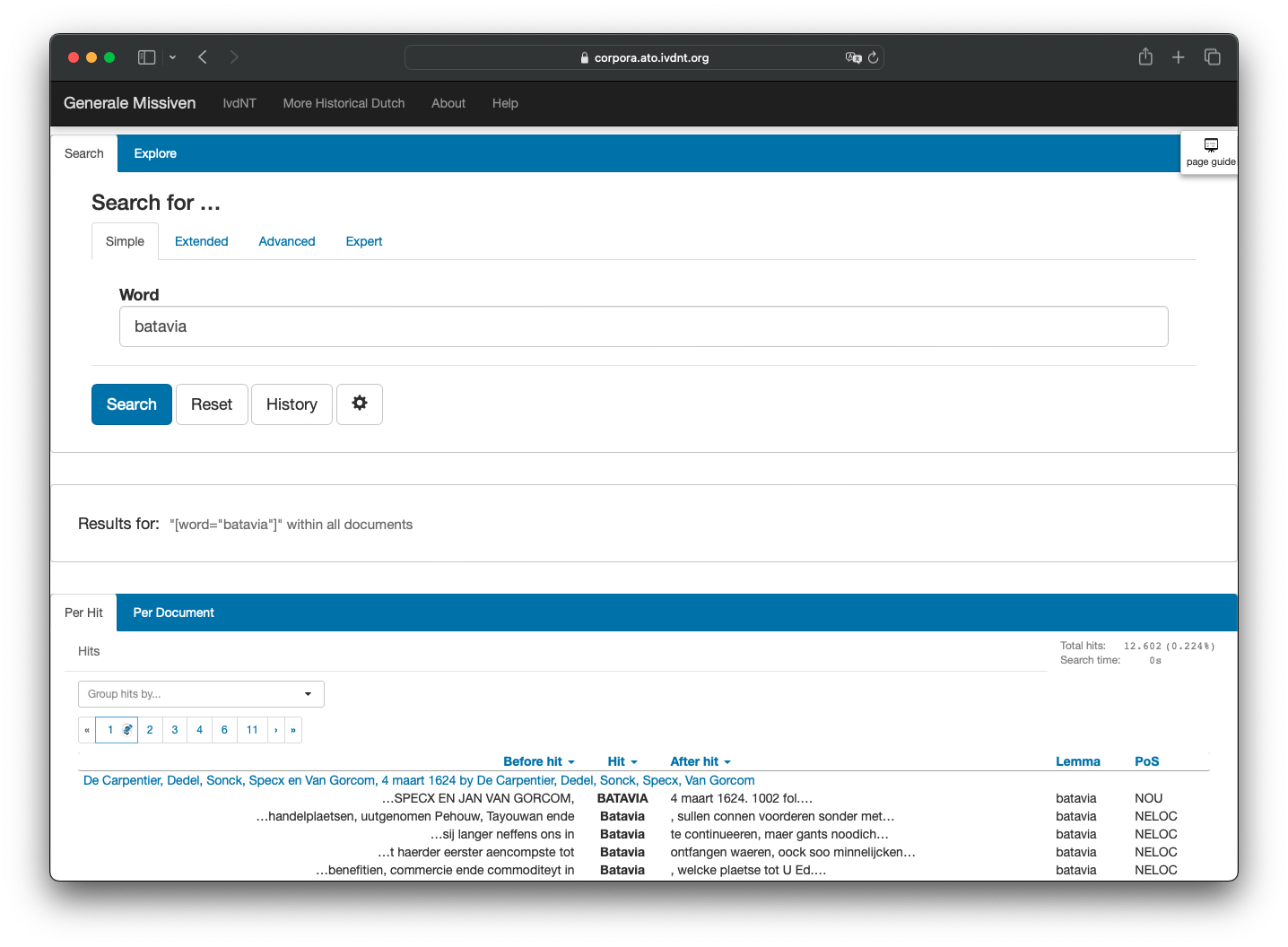
https://corpora.ato.ivdnt.org/corpus-frontend/Missiven/search
The General Missives summarize the information contained in the Overgekomen Brieven en Papieren series of documents from the VOC archives that the GLOBALISE project aimes to unlock for in-depth research. The corpus available in the BlackLab environment is a selection of General Missives from the period 1610-1767 that was transcribed, edited and published in 14 (digital) book volumes by the Huygens Institute and its predecessors. The original volumes are also available online.
Please note that the General Missives contain labels, characterizations and information about persons, actions and events that may be offensive and troubling to individuals and communities.
-
Sophie I. Arnoult, Lodewijk Petram, and Piek Vossen. 2021. Batavia asked for advice. Pretrained language models for Named Entity Recognition in historical texts. In Proceedings of the 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, pages 21–30, Punta Cana, Dominican Republic (online). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.latechclfl-1.3 ↩